Summary
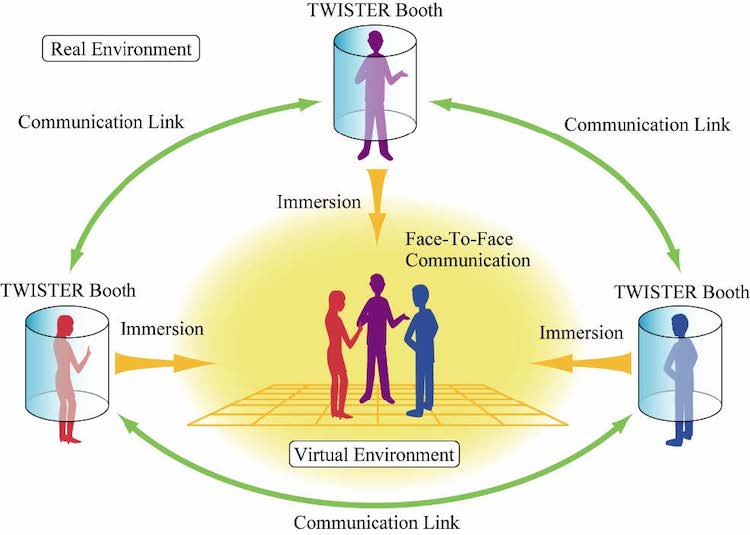
TWISTER has been implemented for face-to-face communication in virtual space (metaverse). As is shown in Figure 1, although the human users are in remote locations, they can meet in a virtual environment (metaverse) as if they meet in person using TWISTER booths.
First, a 360-degree 3D virtual environment is displayed on each booth. Next, the two stereo cameras in each booth capture pictures of the user inside the booth from the angles calculated on the basis of the relative position and orientation of the three users in their virtual environments. The captured images are then transmitted using communication links to the other TWISTERs. Inside each booth, the figures of the other two users are placed in the virtual environment according to their relative position and orientation. In this way, the users sense that they are in close proximity in the virtual environment.
Technology based on the concept of networked telexistence enables users to meet and talk as if they share the same space and time, even if they are located remotely. This is the goal of developing mutual telexistence communication systems, and is a natural progression from telephone to telexistence-videophone.
Figure 1: Face-to face communication using TWISTER booths.
The developed system is designed as a telecommunication system that uses a virtual environment (metaverse) as a place for communication, thereby enabling highly realistic telecommunication between multiple persons. The system is designed to fulfill three conditions: (1) the virtual environment should have highly realistic audiovisual properties; (2) face-to-face communication should allow for eye contact; and (3) participants in the virtual environment should possess a body, and should feel that it belongs to them. We designed and built such a system, and verified its utility.
Specifically, to TWISTER’s omnidirectional, 3D naked eye display, we added a 3D facial image acquisition system that captures expressions and line of sight, and a user motion acquisition system that captures information about arm and hand position and orientation, and we constructed an integrated system whereby communication takes place via an avatar in a virtual environment. We then evaluated the system to verify that it fulfilled the established conditions. Furthermore, the results of having two participants engage in TWISTER-to-TWISTER telecommunication verified that participants can engage in telecommunication in the shared virtual environment under mutually equivalent conditions (Watanabe et al., 2012).
Koichi Watanabe, Kouta Minamizawa, Hideaki Nii and Susumu Tachi: Telexistence into cyberspace using an immersive auto-stereoscopic display, Trans. of the Virtual Reality Society of Japan, Vol.17, No.2, pp91-100 (2012.6) [in Japanese] [PDF]
| Omnidirectional 3D Audiovisual Presentation System | Virtual Environment (Metaverse) and Avatars with Physicality |
| Three-Dimensional Facial Capture System | Motion Capture System | Integrated System |
| Verification of the Telecommunication System |
Omnidirectional 3D Audiovisual Presentation System
We used TWISTER V as a display to present audiovisual images of the virtual environment. As with TWISTER IV, TWISTER V displays binocular images using 36 LED display units, each with separate LED arrays for the left and right eyes. These are equally spaced along a circle with 1 m radius centered on the user, and rotated. Persistence of vision creates a 3D effect regardless of viewing angle, and since parallax images are presented by a rotating parallax barrier mechanism, glasses and other paraphernalia are not necessary to experience the 3D effect.
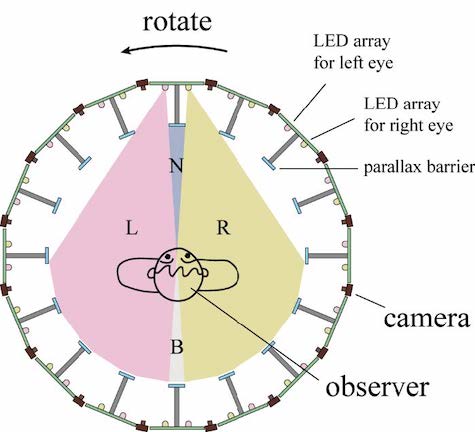
Figure2: Principle of the movable (rotating) parallax barrier method.
Figure 2 shows the principle of the movable parallax barrier method used for TWISTER IV and V. Each display unit contains two LED arrays—one for the left eye, and the other for the right eye. The units rotate at a speed of approximately 1.7 revolutions per second (rps), and the controller synchronizes the display update to create an effective frame rate of 60 frames per second (fps).
Since the parallax barrier obscures LED emission from the opposite side, different images are shown to the left and right eyes. At one moment, only images for the left eye and right eye are observed in areas L and R, respectively. Both images are observed in area B, while neither image is observed in area N. When the display units with barriers rotate around the user, these areas also rotate. The condition of stereopsis is maintained as the display units rotate around the user.
The barrier per se cannot be observed by the observer because it rotates at a speed of 600 degrees per second—the human eye can track a revolution of only approximately 500 degrees per second. This assures a continuous 360-degree panoramic stereo view.
TWISTER V has a 3162 × 600 pixel display resolution, and a 60 fps refresh rate. Users are able to freely move their upper body within the rotating part. Figure 3(a) shows TWISTER V’s exterior, and Fig. 3(b) shows the full circumference of the interior as seen from below. Because images are displayed using persistence of vision during rapid rotation, the cylindrical surface upon which the LED units are affixed can be made transparent, allowing a clear view of the user within (Figure 3(c)).

Figure 3: TWISTER V: (a) general view, (b) view from inside, (c) user seen from outside.
TWISTER V is also equipped with speakers that allow presentation of fully inclusive sound from the bottom of the rotating part. Six speakers are located at a 60° spacing along the periphery, allowing for sound directionality. This allows environmental sounds within the virtual environment and user utterances to be adjusted and presented as sounds within the space along the full periphery.
| Omnidirectional 3D Audiovisual Presentation System | Virtual Environment (Metaverse) and Avatars with Physicality |
| Three-Dimensional Facial Capture System | Motion Capture System | Integrated System |
| Verification of the Telecommunication System |
Virtual Environment (Metaverse) and Avatars with Physicality
We used TWISTER IV and V to create a virtual environment like that shown in Figures 4(a) and 4(b). Users can engage in telexistence via avatars that allow communication while observing the expressions and gestures of others in real time. The space represented in the virtual environment is a 14 × 10 m area, sufficiently large for free movement within. The environment was designed as a futuristic bar, and included objects such as a bar counter, tables, and human-shaped characters. There were glasses on the bar, which could be grasped and picked up by user avatars. The virtual environment was designed so that an image refresh rate of 30 fps could be maintained.
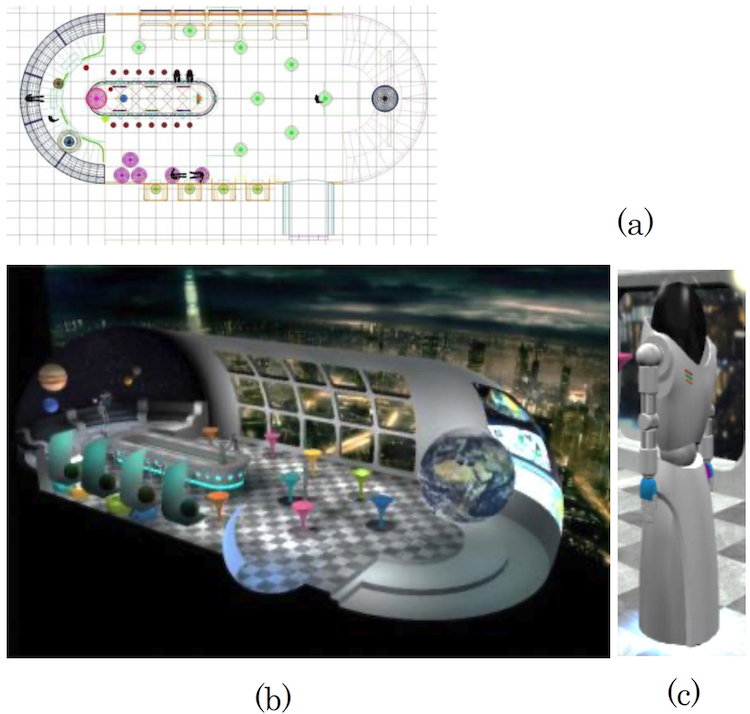
Figure 4: Constructed virtual environment: (a) design drawing of the virtual meeting room with a bar counter, (b) its perspective view, (c) an avatar for use in telexistence communication.
While it is possible to capture full body images for use as avatars, mutual transmission of such images can cause communication latency. We therefore use computer graphics to create avatars, replacing only the head with actual images, due to the importance of facial information during communication. Simply substituting neck-up video for the head of a computer graphics image results in a strange appearance. We therefore designed avatars wearing spacesuits with transparent helmets, and displayed video images of user heads inside the helmets. This makes it appear as if communication partners are wearing spacesuits, reducing the unnaturalness of the situation. Physicality is sufficiently represented by detecting information about arm and hand positioning and orientation and moving the avatar’s arm appropriately, so only such information needs to be sent between systems. We therefore designed the system so that users enter into avatars preexisting within the virtual environment, allowing them to move freely within it.
Figure 4(c) shows an avatar in the virtual environment. Avatar height and shoulder width are equivalent to those of a typical adult male. Each arm has 7 degrees of freedom (DOF) (2 for the shoulder, 2 for the elbow, and 3 for the wrist), and each hand has 8 DOF (3 for the thumb, 1 for each finger, and 1 for abduction). Avatars have wheel-like movement mechanisms that allow them to move parallel to the ground, because mechanisms such as human legs are hard to control, and cause distracting vertical shifting of the image space. The movement mechanism employed allows the user to control movement over a 2D field.
The face portion that embeds the image of the user’s face is a flat oval plate (the “face board,” below) within the transparent helmet. This object rotates to remain directly facing the user, and positioning information is used to paste appropriately front, profile, and back-of-the-head images. Pasting images onto the face board allows users with differently sized heads to use avatars without rebuilding them for each user.
| Omnidirectional 3D Audiovisual Presentation System | Virtual Environment (Metaverse) and Avatars with Physicality |
| Three-Dimensional Facial Capture System | Motion Capture System | Integrated System |
| Verification of the Telecommunication System |
Three-Dimensional Facial Capture System
Figure 5 shows the details of the TWISTER camera system used for user face capture. Taking advantage of the transparency of TWISTER, we have mounted a self-propelled stereo camera to the external periphery. TWISTER’s interior is visible from the exterior, but from inside only the displayed video image is visible. This allows the user to ignore the presence of the camera, and better immerse into the virtual environment. Because TWISTER does not require that users wear glasses or other devices over their faces, video images of user expressions can be directly captured.
Figure 5(a) shows a self-propelled camera, and Fig. 5(b) shows the 1.2 m radius circular rail on which it runs. Multiple cameras run along the TWISTER periphery, oriented to face its center. The rail is positioned at the eye height of the user inside the TWISTER device, and can be raised or lowered to accommodate users of different heights. The self-propelled stereo camera positions its camera elements (Firefly MV, Point Grey Research) 65 mm apart to mimic the average spacing between human eyes, and can move freely along the rail using motors mounted to their bottoms. Their horizontal and vertical viewing angles are 17 degrees and 13 degrees , respectively, so a 0.36 × 0.27 m area can be photographed from 1.2 m away. The average height of a Japanese male face is 0.24 m, so this range is sufficient. The camera has a 30 fps refresh rate for a 640 × 480 pixel image size.
To better accommodate multiuser applications and mechanical issues such as wiring, the TWISTER periphery is divided into three areas, and two self-propelled cameras are installed for each area. The cameras use information about the positioning and orientation of other users in the TWISTER environment to determine the angle from which user images should be acquired, then move to that location and begin capturing images. This allows directional alignment of the avatars and cameras such that cameras work as avatar eyes, acquiring facial images according to the line of sight of other users in the environment. Acquired images are sent to other users, and pasted onto the avatar representing the imaged user. As described in the section regarding avatar design, face boards pivot so that they are always facing other users, so the images captured by cameras can be pasted as-is onto the face boards to allow other users to view faces according to the appropriate positioning information.
Figure 5(c) shows the positional relation between the avatar and the face board. When another user moves sideways while viewing the imaged user, the imaged user’s profile is captured and pasted onto the face board, giving the impression of a 3D image. Since a small number of cameras can acquire images from any direction, rather than assigning a single self-propelled camera to each other user in the virtual environment, the positional relationship with other users is used to appropriately select images in real time, switching between cameras as needed. When cameras are switched, the new camera moves as closely as possible to the imaging one, to make the switch as smooth as possible. The mechanisms and controls described above are used to make possible communication in which line of sight can be aligned.
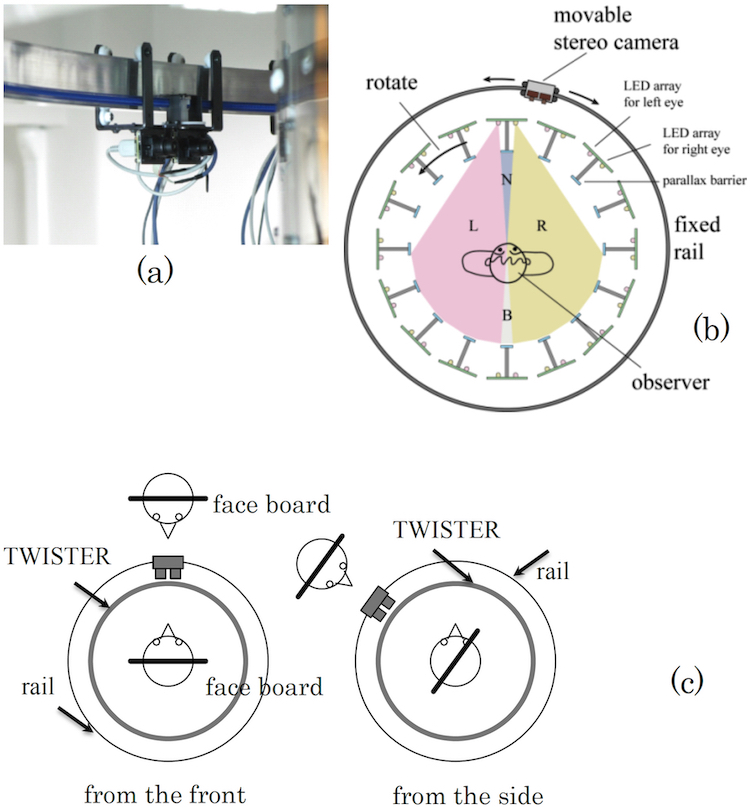
Figure 5: Movable stereo camera: (a) general view, (b) same as Fig. 1, (c) relationship between the face board of the avatar and the camera.
When there are three or more users in the same virtual environment, a camera that can move to a position capable of capturing images from the appropriate location is assigned to each. When other users in the virtual environment pass by each other, it becomes necessary to change the cameras assigned to them. Figure 6 shows an example of two users passing by each other, and the resulting camera reassignment. When two users start from positions like those shown in the left figure and move toward each other, the configuration becomes like that shown in the middle diagram, and two cameras will move to an almost colliding position.
As the users pass by each other, the camera space positioning remains as it is, and the camera assignments are electronically switched so that the camera that was capturing user C from user A’s point of view becomes the point of view of user B, while the camera that was capturing user C from user B’s point of view becomes the point of view from user A. The cameras are now in a state like that in the right diagram, and continue capturing their newly assigned users. Controlling camera assignments in this manner allows continuous 3D facial imaging without regard for physical limitations on camera locations, even when there are multiple users moving about in the virtual environment. A headset captures voices. Using a headset ensures that voices are captured without inhibiting facial expressions or eye and mouth movement.
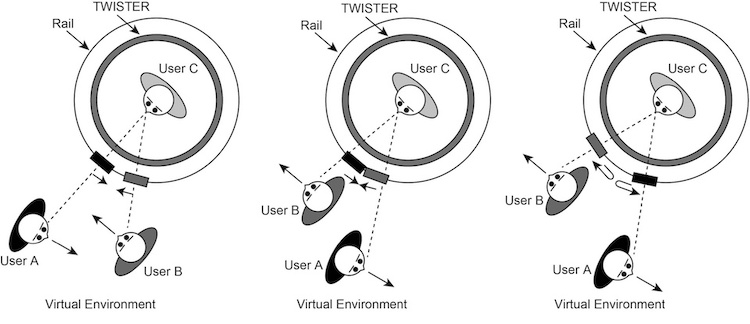
Figure 6: Algorithm for changing cameras when two users pass by each other.
| Omnidirectional 3D Audiovisual Presentation System | Virtual Environment (Metaverse) and Avatars with Physicality |
| Three-Dimensional Facial Capture System | Motion Capture System | Integrated System |
| Verification of the Telecommunication System |
Motion Capture System
The system uses a combination of optical motion capture and joystick input to capture hand and arm positioning information for intuitive physicality when grasping or moving objects, and when making gestures. There are contact and noncontact methods of motion capture, but we adopted a noncontact method that emphasizes low movement restrictions over measurement accuracy to better allow for gestures.
One limitation of noncontact methods is occlusion of hand movements, however, and because we require some level of stability in grasping and finger gestures, we also incorporated use of a worn data glove. Avatar movement is controlled by the joystick. Avatar design is for legs that assume movement in an omnidirectional wheel parallel to the ground, so joystick-based movement controls are better suited than are direct input methods such as walking motions using the feet.
Figure 7 shows details of the system used to capture TWISTER user motions. We attach an infrared optical motion capture system (OptiTrack V100:R2, NaturalPoint, Inc.) to the right arm, and position the infrared camera so that the entire upper body of the user inside the TWISTER rotating body can be imaged throughout its entire 1 m radius. Absolute positions within the 3D space are measured via infrared markers on the wrist, elbow, and shoulder of the right arm.
Wrist position is calculated using the shoulder position as a basis, and reverse kinematics is used to calculate joint angles in consideration of the elbow position. This information is passed on to the avatar, whose 7 DOF for the arm can perfectly reproduce the arm’s 6 DOF and elbow’s 1 DOF obtained from the position and orientation of the hand with respect to the shoulder. Marker locations are calculated with less than 10 ms of latency.
A data glove (5DT Data Glove Ultra, Fifth Dimension Technologies) on the right hand acquires hand movements. This glove can capture the joint angles of all five fingers. DOF calculations other than the 5 DOF that can be captured from the data glove are inferred from the acquired information. Latency from the data glove is less than 13 ms. Grip gestures from the data glove can be interpreted in consideration of cups and other movable objects within the virtual environment, allowing them to be moved freely. There is no motion capture equipment on the left arm or hand, which is dedicated to movement throughout the virtual environment using the joystick. The joystick has 3 DOF (front/back translation, left/right translation, clockwise/counterclockwise rotation), allowing free movement within the virtual environment. To maintain continuity between user motion and the avatar in the virtual environment, the avatar, too, holds a joystick in its left hand, which it operates in accordance with the user.
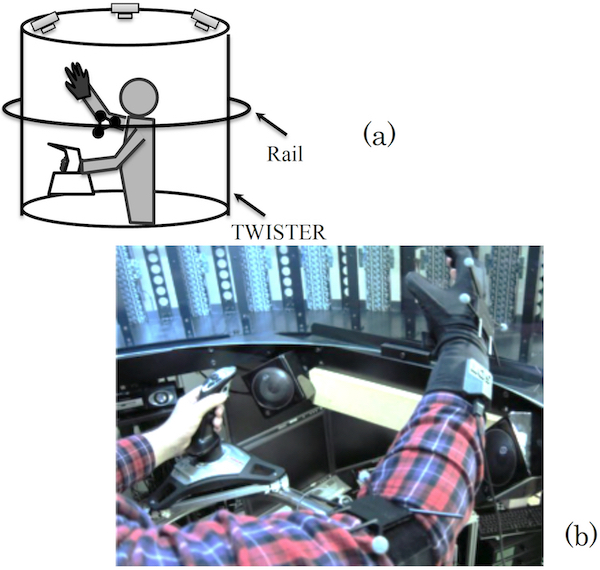
Figure 7: System for capturing user’s hand motions: (a) layout of optical markers and a joystick, (b) general view of the motion capture system layout.
| Omnidirectional 3D Audiovisual Presentation System | Virtual Environment (Metaverse) and Avatars with Physicality |
| Three-Dimensional Facial Capture System | Motion Capture System | Integrated System |
| Verification of the Telecommunication System |
Integrated System
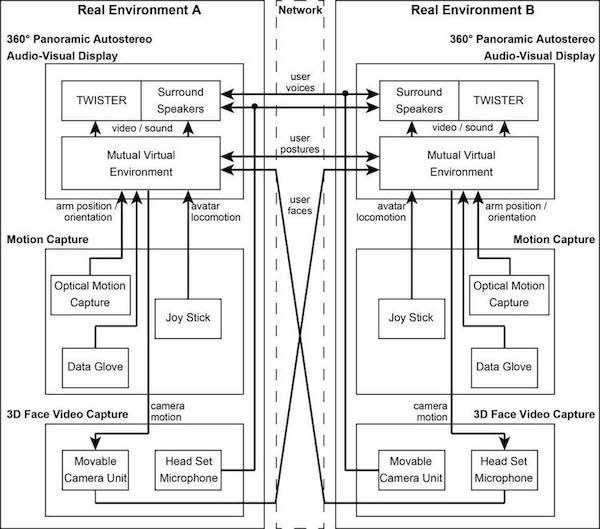
Figure 8: Configuration of the proposed telexistence communication system.
Figure 8 shows a telecommunication system that incorporates two TWISTER units according to the conceptual diagram in Fig. 1. This omnidirectional 3D audiovisual system uses TWISTER for image presentation and peripheral speakers to share virtual environment information. The movement acquisition system uses optical motion capture, a data glove, and a joystick, and information about user hand and arm positioning and orientation is used to calculate avatar movements that are sent to the system. Information other than user facial images and utterances are collected, and differential information between the virtual environments is mutually transmitted using the UDP protocol to reflect changes in the virtual environment.
The 3D facial imaging system has a mobile camera unit and a headset microphone. The mobile camera unit uses avatar positional relations from the virtual environment to determine required camera movements, and controls self-propelled stereo cameras so that they are appropriately positioned. Captured user facial images are sent directly via a network to the virtual environment of other users. User utterances acquired by the headset microphone are sent via the network to the peripheral speakers of the user and others in the virtual environment, where they are presented along with environmental sounds.
| Omnidirectional 3D Audiovisual Presentation System | Virtual Environment (Metaverse) and Avatars with Physicality |
| Three-Dimensional Facial Capture System | Motion Capture System | Integrated System |
| Verification of the Telecommunication System |
Verification of the Telecommunication System
We used a communications experiment to verify the telecommunication system, ensuring that the established requirements were sufficiently fulfilled to allow smooth communications in a shared virtual environment. The experiment was performed between two remote users engaged in one-on-one communications using TWISTER. The users were located on the University of Tokyo Hongo Campus (Hongo, Bunkyo Ward, Tokyo) and the Keio University Hiyoshi Campus (Hiyoshi, Yokohama). The network between the two TWISTER systems was over a dedicated 10 GB Ethernet line. Six participants took part (three at each location), each in his or her 20s. Two pairs of participants between the locations used the system in turn for approximately 30 min each, and one pair used it for approximately 2 h. Figure 9 shows examples of the virtual meeting room projected in TWISTERs.

Figure 9: Examples of the virtual meeting room projected in TWISTER: (a) left-eye view, (b) right-eye view.
Figure 10(a) shows the presentation of a facial image onto an avatar face area as seen from the front, while Figure10(b) shows the projection as seen from the side, which is presented as an appropriate 3D profile image. Figure 10(c) shows the position of the stereo camera and the avatar, with TWISTER external illumination adjusted so that both can be seen. The stereo camera overlaps the avatar’s facial position, so that line of sight naturally aligns. We verified that an avatar with physicality similar to a human’s can be used in a virtual environment for free movement, gestures, and transport of virtual objects such as glasses.

Figure 10: User avatar in telexistence communication: (a) front view of the user face, (b) side view of the user face, (c) camera overlapping with the avatar.

Figure 11: Gestures: (a) hand-waving motion, (b) pointing motion, (c) mimic drinking.
Figures 11(a) and (b) show users performing gestures of waving and pointing. Figure 11(c) shows an avatar holding a glass.
We performed a logical verification that component performance in the constructed system was sufficient to allow movement representation with acceptable latency. Calculation of hand and arm movement latency is based on the 13 ms latency rating of the data glove. Acquiring the measurement data with a PC and preparing it for UDP transmission has a latency of approximately 10 ms, after which it is sent. Data transferred over the network concerns only the positioning and orientation of avatars and mobile objects, and so is quite small (approximately 100 bytes). Transfer latency is therefore taken to be approximately 10 ms. Receipt processing of the UDP packets is approximately 10 ms, and reflecting these data on presented images takes at most 30 ms. The total is therefore 73 ms. We take this to be sufficiently small, given that the limits of human latency perception is in the range of 100 to 200 ms.
We performed a similar latency estimate for facial images of the communication partner to predict latency of movement vision. Steps requiring processing time are image acquisition (30 ms), PC capture (30 ms), encoding (approximately 10 ms), transmission and shared file creation (approximately 30 ms), reading and decoding (approximately 30 ms), and image updates (30 ms), for a total estimate of 160 ms. This is fairly high, based on a permissible latency range of 100 to 200 ms, but within the upper limit. Some perceptible latency regarding expressions through facial imaging is also likely permissible when supplemented by voice and gesture latencies that are less than perceptible limits, and since latency of hand and arm gestures is approximately 73 ms we consider that synchronization of the shared space is sufficiently attained. Because the amount of exchanged data is quite small given the capabilities of the network used, we believe it possible to increase the number of participating users and mobile objects while still remaining within the bounds of transmission latency requirements.
Figure 12 shows the results of telecommunication in the integrated system. Figure 7.36(a) is an image of the TWISTER booth located at Keio University, and (b) shows the booth at the University of Tokyo. We confirmed that the basic flow of the experiment could be conducted without significant problems.

Figure 12: TWISTER to TWISTER communication: (a) a view from TWISTER V at Keio University, (b) a view from TWISTER IV at The University of Tokyo.
Subjective evaluations of the system from experiment participants were unanimous in reporting that interactions in the virtual environment invoked feeling similar to performing the interactions in the real world. One participant reported the experience as being not so much like having one’s body transported to the virtual environment, but rather as if the TWISTER booth itself had been transported. We interpret this as meaning that entering the virtual environment in clothing similar to a space suit invoked a feeling of near immersion. Demonstrative pronouns frequently used in the real world such as “there” and “this” were naturally understood, leading to opinions that communication was easily performed. Such qualitative results are further indications that the proposed requirements were all met, and that telecommunication that includes physicality and transmission of intent was realized.